2026-06-24
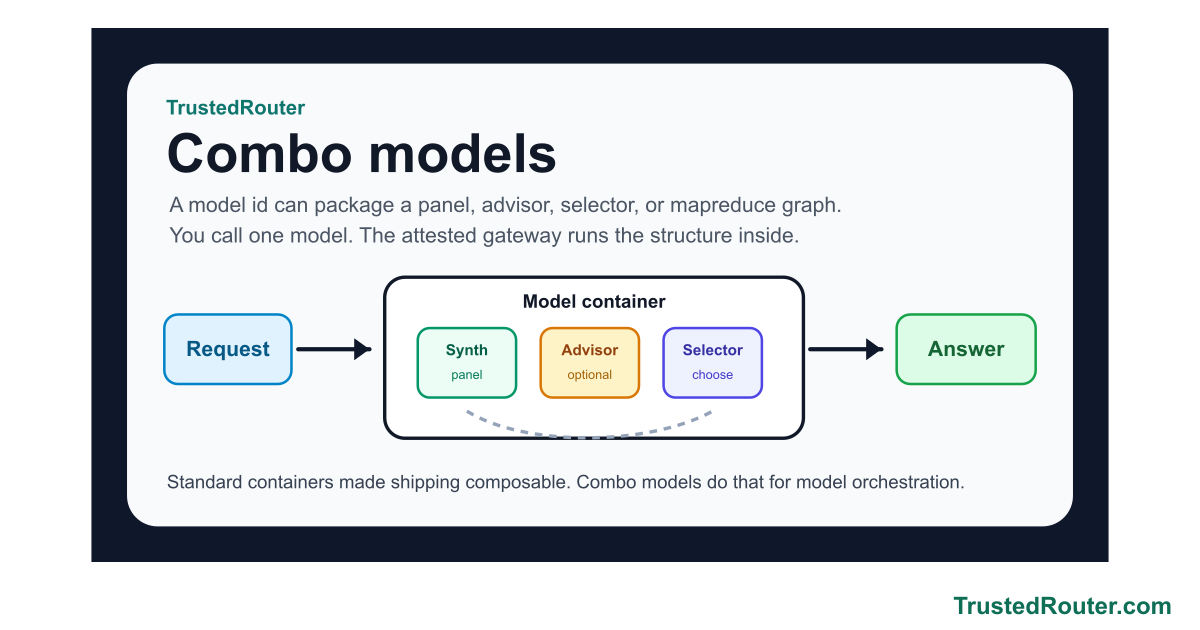
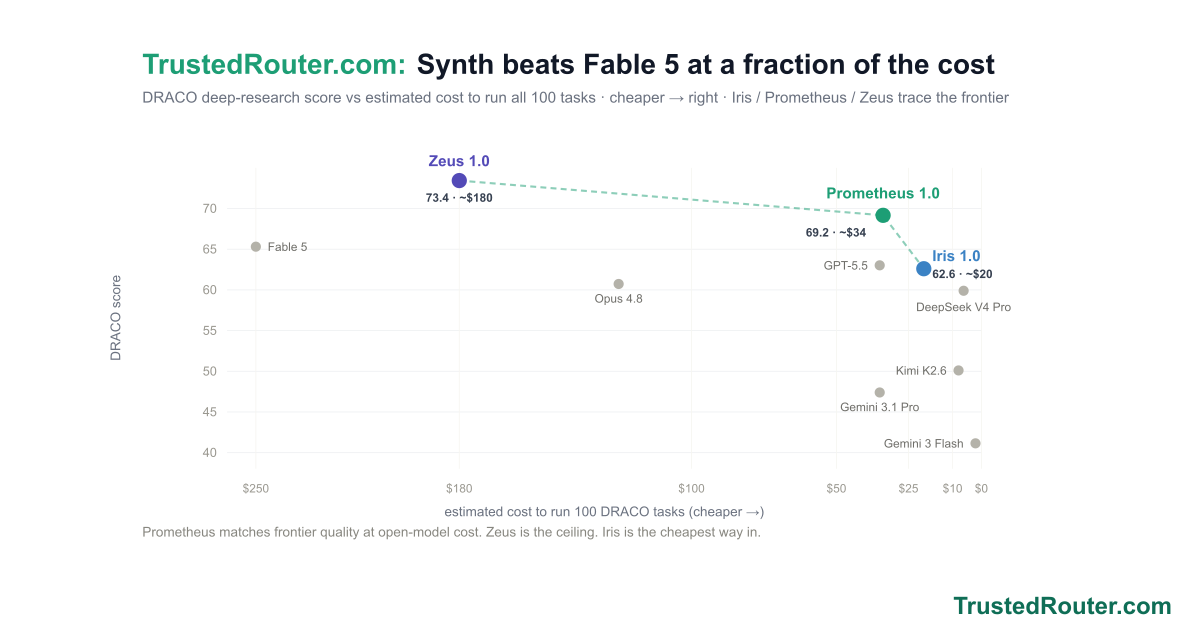
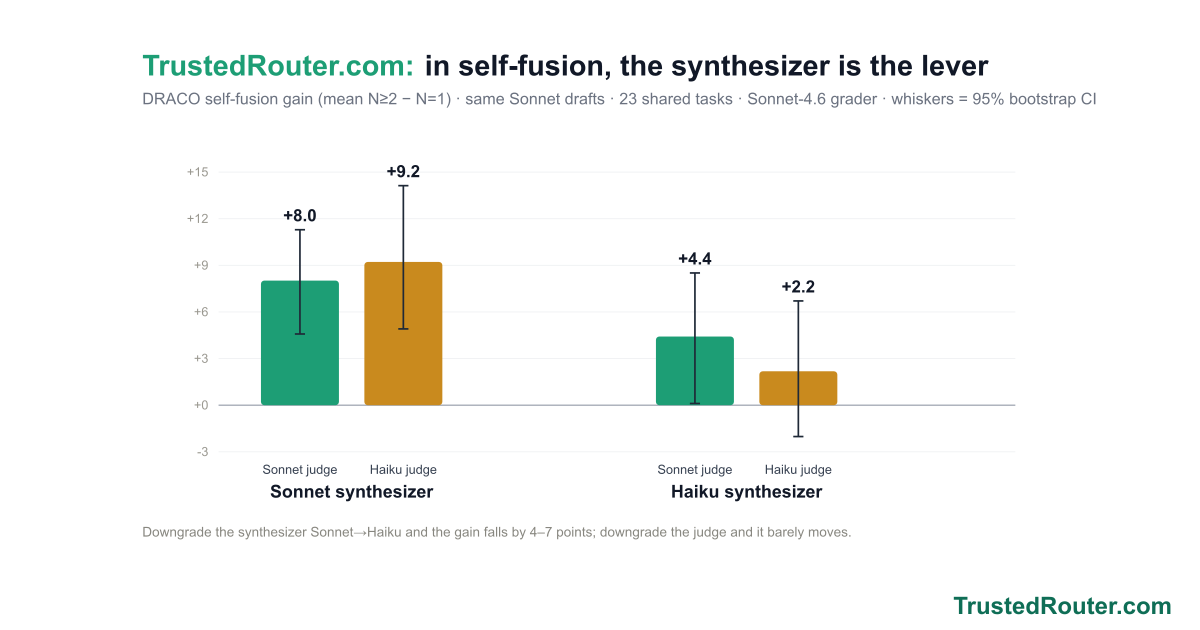
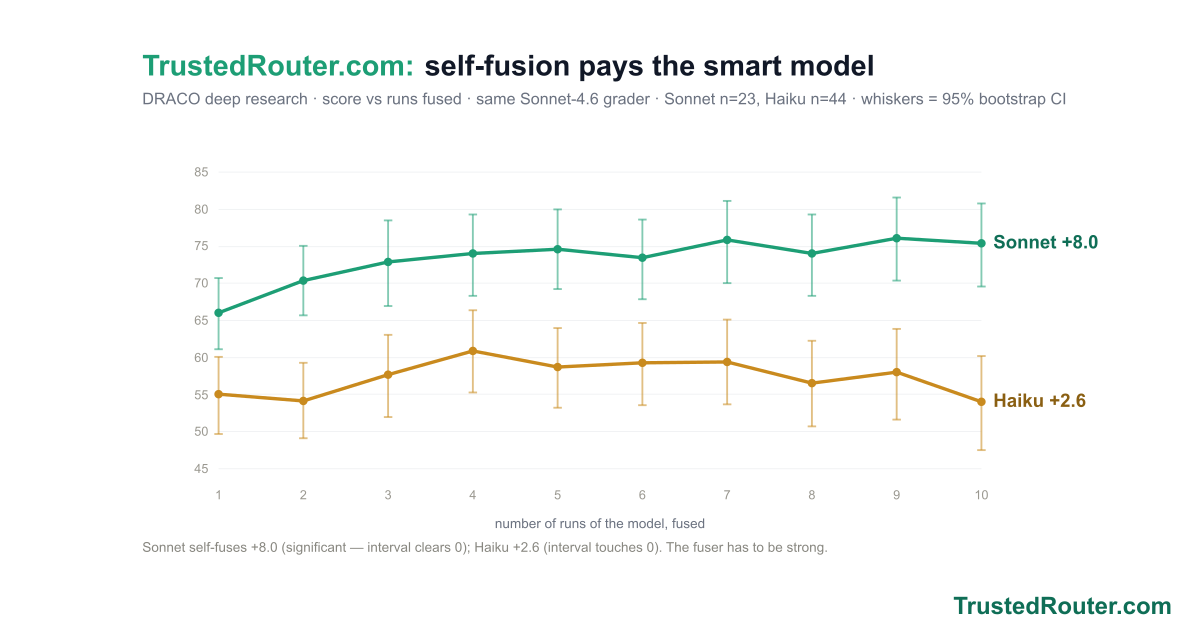
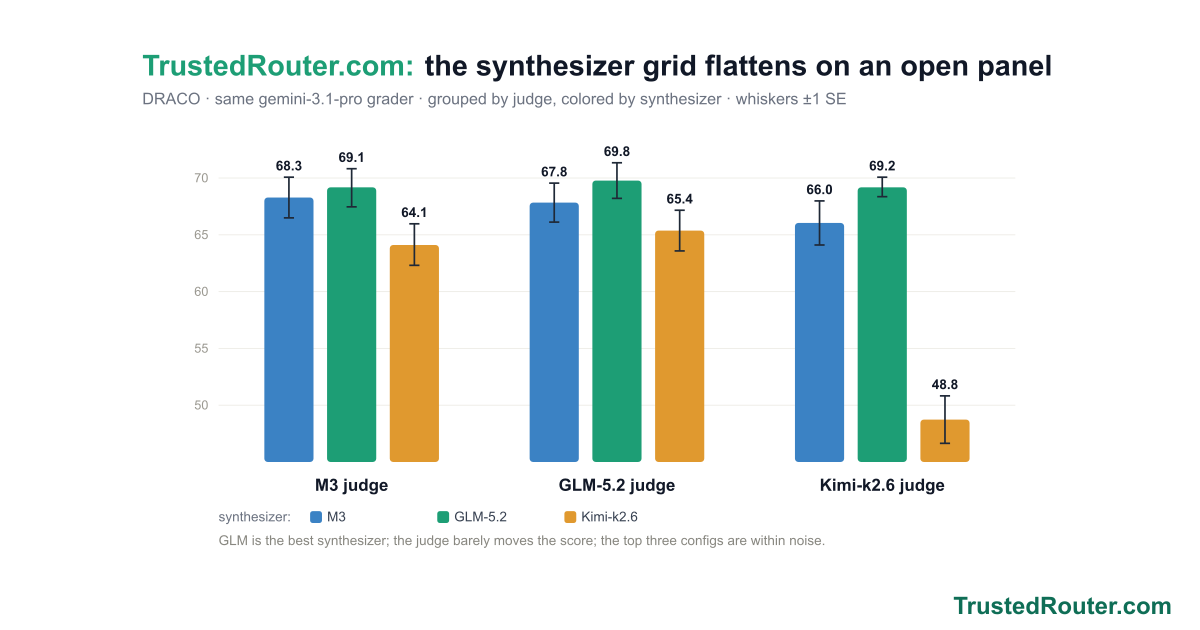
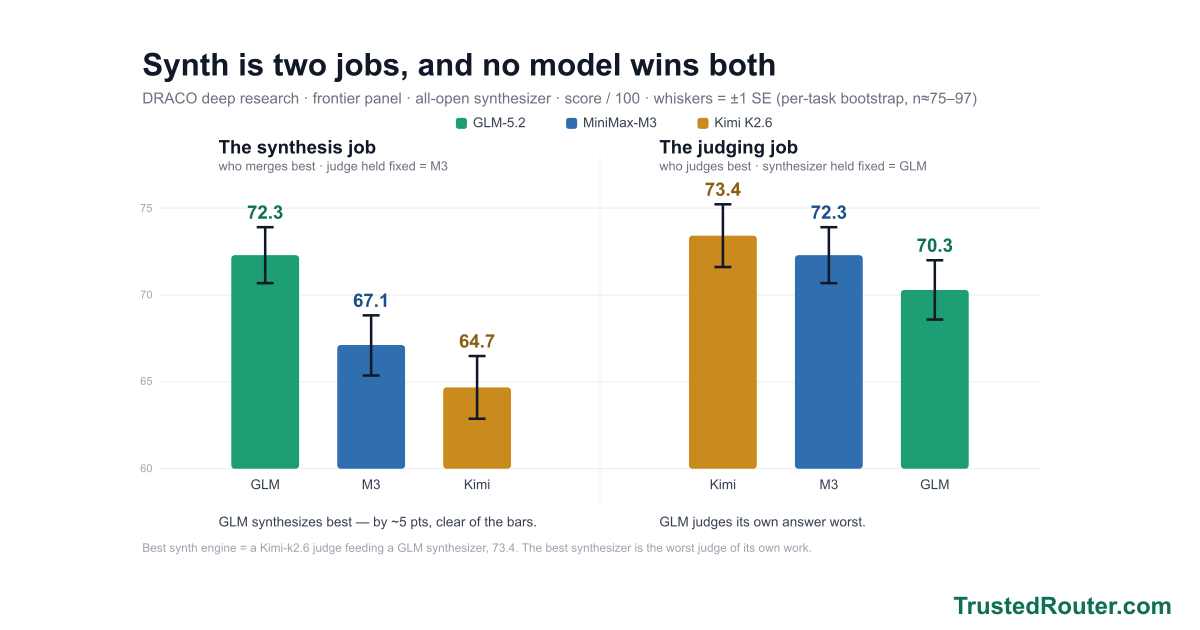
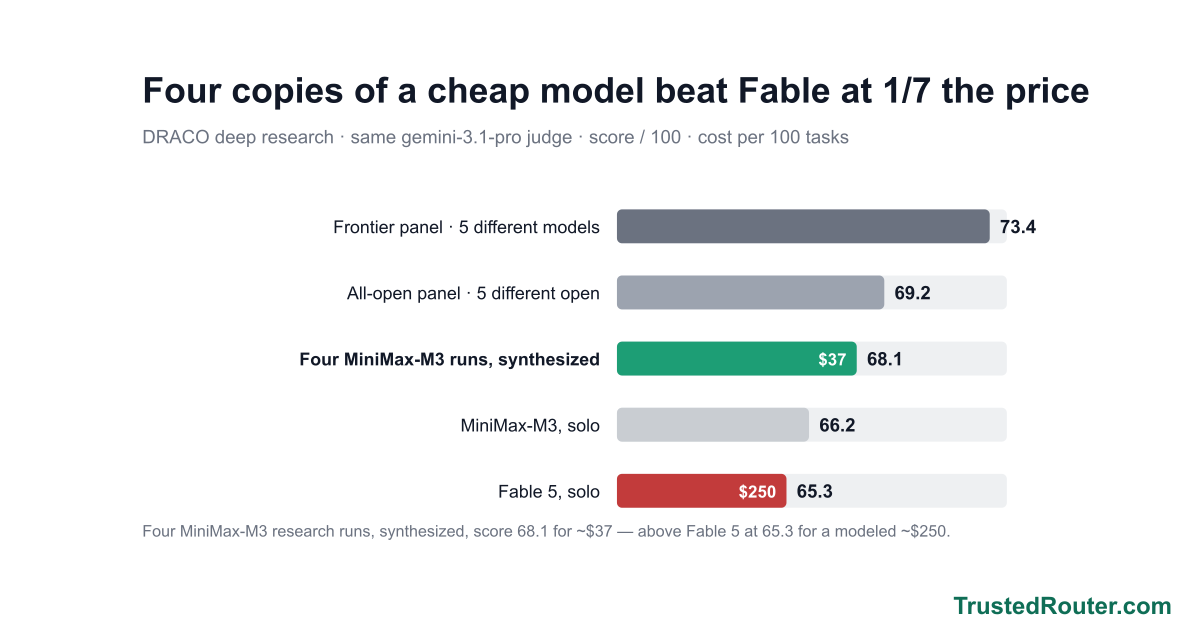
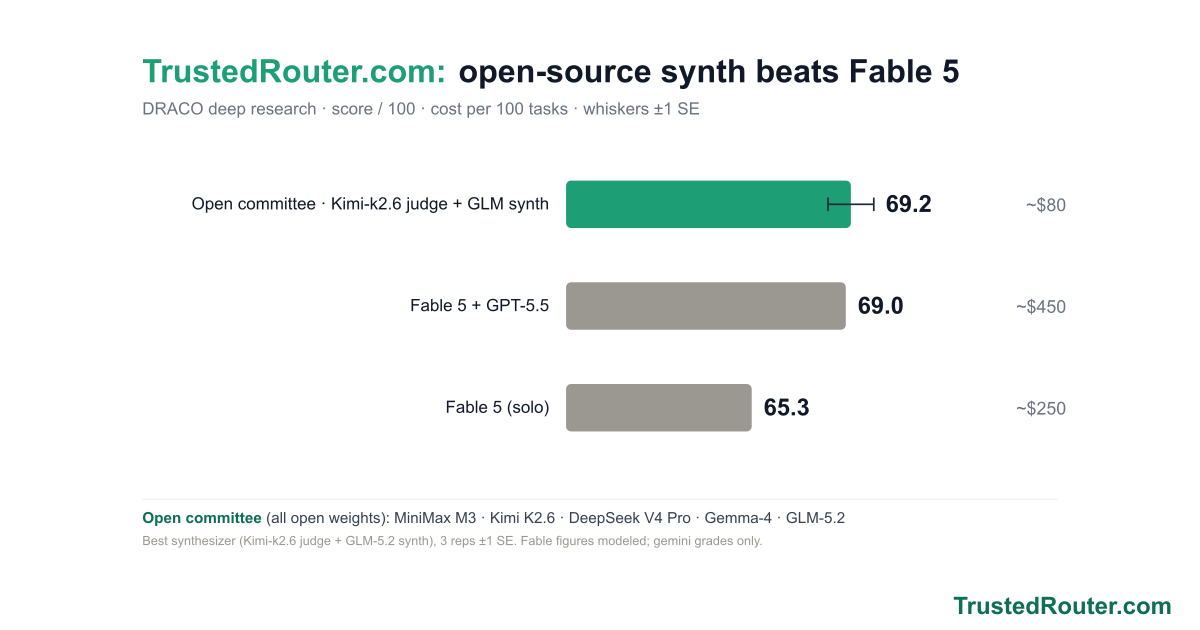
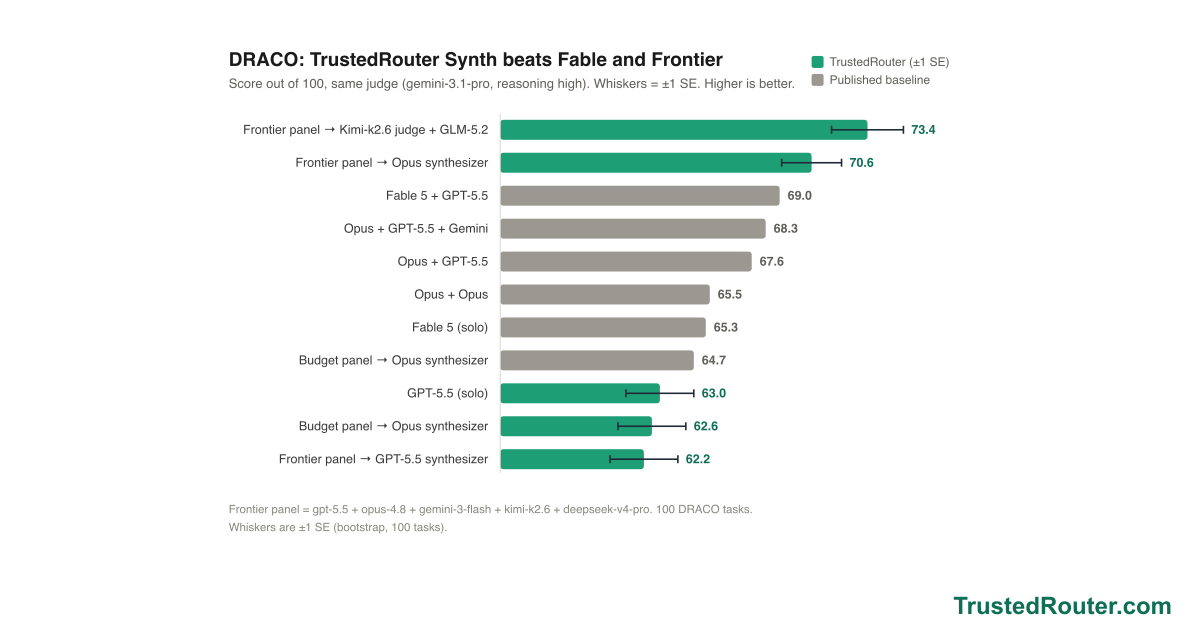
Synth now ships as three named presets — Iris 1.0 (trustedrouter/iris), Prometheus 1.0 (trustedrouter/prometheus), and Zeus 1.0 (trustedrouter/zeus) — one fusion engine, three panels. On a score-vs-cost chart of DRACO deep research they trace the efficient frontier: Prometheus scores 69.2 at open-model cost, beating Fable 5 (65.3) for roughly a seventh of the price; Zeus tops out at 73.4, the state of the art; Iris is the cheapest way in at 62.6. And for code and the agents that write it, trustedrouter/synth-code is the same fusion tuned end to end — code-specific panel and synthesis prompts and a code-tuned judge.
Read →
Source: TrustedRouter-Fusion-Draco on GitHub